
반응형
04. 부속 프로세싱 - 이미지 처리 기술과 검색 기술의 융합
intro
- 검색 엔진, 그리고 정보처리엔진 이런 것에는 문자나 텍스트만으로 국한될 필요는 없다. 실제로 우리가 디지털화할 수 있는 모든 데이터 , 즉 이미지 데이터 , 비디오, 동영상, 3D 이미지, 그리고 속성들 그리고 들릴 수 있는 소리, 가상현실 등등 여러가지 데이터들의 의미를 처리할 수 있다.
- 검색 엔진은 문자뿐만아니라 이미지 등 여러가지 있는 뜻을 추출해 우리가 색인할 수 있고, 그런 색인된 정보를 추출해줄 수 있는 정보를 볼 수 있다.
- 우리가 이 섹션에서는 이미지 검색을 예로 들지만, 이것을 통래 우리는 문자뿐만 아니라, 여러가지 부속적인 다른 방식의 데이터들도 색인이 가능하고, 이것을 통해 우리가 검색 기술을 확장할 수 있다.

- 핀터레스트가 이런 질의 품질을 보여줄 수 있었던 과정은 빨강, 꽃 이러한 단어를 그자리에서 클래시피케이션한 것이 아니라, 오프라인으로 먼저 클래시피케이션하고, 이렇게 인지를 한 다음에 이것을 색인하여 이런 문서들에 추가를 함으로써 이렇게 RED FLOWER를 찾을때, 빨리빨리 , 그리고 매우 실시간으로 찾아줄 수 있는 결과를 가져오는 것이다.
- 이미지 클래시피케이션과 지식그래프를 이용해 어마어마한 것을 할 수 있다. (비슷한 이미지 찾기, 같은 이미지 찾기 ,..)
- 또한, 이러한 이미지 검색을 사용할 수 있는 요소들이 있다면, 꽃뿐만 아니라 사람의 얼굴까지도 판단할 수 있다.
- 예를 들어, 반테러리즘을 위한 검색엔진을 만들겠다고 했을 때, 여러 사람들의 안면인식을 통해 비슷한 이미지가 어디서 나왔는지, 이사람 포스팅이 다른 소셜 네트워크의 어떤 사람과 연결되어있는지, 해서 이러한 네트워크를 구성하는데 도움이 될 수 있으며, 이 사람이 어느 cctv 에 포착이 되었을 떄, 이 포착된 사람이 다른 cctv 의 어느 이미지에 포착이 됐다. 이런 것을 통해 이 사람의 동선을 확인할 수 있고, 코로나 같은 재난 상황에서 동선을 확인하고, 격리대책을 만드는 데 도움을 줄 수 있는 이런 기술도 쉽게 만들 수 있다.
이미지 검색 활용도
- 유사 이미지 검색
- 이미지, 동영상 저작권 검색
- 유사한 제품 검색
- 시장조사 ( 티비 시청률, sns 인지도 )
- 메타 데이터 추론 및 추출
이미지 검색 사례
유사 이미지 검색
섹션으로 쪼개서 벡터화 : 픽셀로 잘라 해시를 적용
- 같은 이미지 찾기 가능,
- 민들레를 섹션으로 쪼개 관찰해보면, 각 섹션에 민들레만 가질 수 있는 고유한 패턴(씨의 배열, 노랑-검정의 규칙적인 패턴)이 있을 수 있다.
- 여기서 봤을때, 그러면 이런 섹션들을 쪼개서 RGB 로 나눠 우리가 만약에 추출을 하면, 추출해 => 배열화하고=> 이 벡터를 해시화해서, 이 해시를 가진 이미지가 있다고 하는 경우, 왼쪽에 있는 민들레와 정확히 동일한 다른 이미지가 있다하면 이렇게 각 섹션마다 나누어서 해기를 만들어서 유사 일치를 하였을 떄는 일대일 매치가 나올 것입니다. 그래서 정확히 동일한 이미지가 나올 것입니다.
- 만약에, 그 이미지가 조금이라도 잘렸다/ 크기가 스케일링 되었다, 하면, 이 섹션들이 만들어지는 데 문제가 생길 것입니다. 그래서 이 방법은 동일 이미지 자체에는 사용할 수 있겠지만, 유사이미지는 찾을 수 없을 듯 합니다.

이미지에서 독특한 패턴 찾기: 이미지 자체에 있는 패턴 찾기
- 유사 이미지 찾기
- 예를들어 이 배경과 하얀색이 만들어진 contour 을 우리가 표현해보았다. 이렇게 하면, 이런식의 패턴, 이런 움직임 굴곡들이 보일 수 있다.
- 이런식으로 약간의 유사성을 확인할 수 있다.
- 실제로 이 방식은 이미지 검색에서 매우 많이 사용되고 있다.
- 우리는 이것을 square invariant feature transformation 이라 한다.
- 이미지가 작던지 크던지간에 상관없이 이렇게 같은 사이즈가 아니라해도 이 변화의 굴곡, 그리고 이 패턴만을 사용함으로써 그래서 이 변화가 어떻게 되는지 이것만을 기록함으로써 이미지가 작아지거나 커지더라도 확인할 수 있는 이런 방법들을 사용하는 알고리즘들이 있다.
- 이런 형태로 유사 이미지검색이 가능해진다.
- 한계: 같은 이미지들이 뭉쳐있는 경우, 아웃라인이 뭉개져 유사 이미지 검색이 안될 수 있다.
- 즉,여기서 cnn 등을 이용해 이미지 자체에 있는 인퍼런스를 추론하는 방식으로 할 것 입니다.
- 하지만, 우리가 AI 로 들어가기 전에도 이러한 방식으로 여러가지 이미지 검색에 대한 결과를 찾아낼 수 있고, 추출할 수 있달 보여줬다.

두 가지 융합도 가능하다.
- 그래서 이렇게 우리가 Contour 를 만들어냈을 때, 이런 contour 사이에서 이제 이 비트 관련 해시를 만들 수 있다.
- 그래서 각 부문마다 이렇게 해시를 나타내는 방식과 이렇게 contour 나타내는 방식 두개를 융합해보면, 우리가 만약에 이 contour 사이에 있는 부분만 이렇게 잘라서 여기서 비트를 이렇게 나눠볼 수 있을 것입니다.
- 이 두개로 유사이미지 여부 판단은 매우 쉬워질 것이다.
- 물론 이 검색 이미지에 추론을 더 추가하면 매우 정확도가 올라갈 것이다. 그래서 우리가 cnn 을 사용해 이런 추론의 정확도를 높이는 것 또한 같이 실습해보겠습니다.
동영상 저작권 검색
- 각 이미지 프레임마다 이미지 검색을 통해 이렇게 동영상의 저작권이나 아니면 동영상이 있는 여러 가지 추론을 만들어낼 수 있겠지만, 만약에 동영상이 있고, 이 비슷한 동영상이 존재하는데, 유사 여부 판단은 이미지 자체 데이터뿐만아니라, 민들레가 움직이는 방식, = 비트가 움직이는 방식을 통해 유사도 + 저작권 추론을 하고 있다.
- 이 방식과 유사하게, 음악에도 적용되는데 소리가 움직이는 방식, 어떤 프리퀀시에서 몇 초 사이에서 스파이크가 있다 없다 똰, 우리가 이 변화 자체를 검색엔진에 색인할 수 있다. 그것을 통해 유사 음악이다 아니다를 처리할 수 있다.

- 이렇게 이미지, 영상, 음악, 가상현실 등이 색인이 가능하다.
이미지 색상 검색 실습1
- 이번 실습은 아주 간단하게 이미지들을 처리해서 이미지에 있는 raw(red, green , blue) 색상만 검색하는 방식으로 실습을 진행해볼 예정입니다.
- 이번에는 이미지들을 하나씩 처리함으로써 나오는 색상을 그냥 키워드에 추가하는 식으로 해서 진행을 해보겠습니다.
- 이번 실습 목표 : 고급 이미지 처리가 아니라, 이미지 또한 로드함으로써 무엇인가 추가 데이터를 처리할 수 있다. 또하느 이러한 추론을 통해 여러 키워드 확장이 가능하다. 이것을 보여주는 취지이다.
인덱스
변화 없음. keywords 라는 이 메타데이터만 가지고, 작업을 진행함.
ingestor
- flower_classifier
# ingestor/flower_classifier/raw_color.py
from PIL import Image
import numpy as np
def get_dominant_rgb(image_file):
# r, g, b 중에 어떤 색이 dominant 한지 알아보는 함수
im = Image.open(image_file)
pix = im.load()
width = im.size[0]
height = im.size[1]
rgb_counters = { 'red': 0, 'green': 0, 'blue': 0}
for y in range(0, height):
for x in range(0, width):
r,g,b = im.getpixel((x, y))
rgb_counters[get_dominant_raw_color(r, g, b)] += 1
highest_count = np.max(list(rgb_counters.values()))
for k, v in rgb_counters.items():
if v == highest_count:
print(k)
return k
def get_dominant_raw_color(r,g,b): # 255 30 199 => red
max_value = np.max([r,g,b])
if r == max_value:
return 'red'
if g == max_value:
return 'green'
return 'blue우세한 색상 키워드로 삽입
import ast
import datetime
import hashlib
import json
import mysql.connector
import requests
import kg.kg_loader as kg_loader
import flower_classifier.tf_classifier as classifier
import flower_classifier.raw_color as raw_color
# SQL 에 연결하여 제품 페이지들을 추출하여 ProductPost array 로 돌려주는 함수입니다
def getPostings():
wp_attachments_prefix = '../www/wp-content/uploads/' # 데이터베이스에 있는 이미지들이 이러한 파일 로케이션에 있기 떄문에 파일 이름을 쉽게 받아주기 위해 이런 prefix 를 넣었다.
wp_attachments_url_prefix = 'http://localhost:8000/wp-content/uploads/' # 웹에서 찾을 떄, prefix
kg_source = 'kg/kowiki-20210701-pages-articles-multistream-extracted.xml'
wiki_kg = kg_loader.loadWikimedia(kg_source)
cnx = mysql.connector.connect(user='root',
password='my_secret_pw',
host='localhost',
port=9906,
database='flowermall')
cursor = cnx.cursor()
# 2. Flower model 을 train 합니다.
# class_names, model = classifier.build_flower_model()
query = ('SELECT posts.ID AS id, posts.post_content AS content, posts.post_title AS title, posts.guid AS post_url, posts.post_date AS post_date, posts.post_modified AS modified_date, metadata.meta_value AS meta_value, image_data.meta_value AS image FROM wp_posts AS posts JOIN wp_postmeta AS image_metadata ON image_metadata.post_id = posts.ID JOIN wp_postmeta AS image_data ON image_data.post_id = image_metadata.meta_value JOIN wp_postmeta AS metadata ON metadata.post_id = posts.ID WHERE posts.post_status = "publish" AND posts.post_type = "product" AND metadata.meta_key = "_product_attributes" AND image_metadata.meta_key = "_thumbnail_id" AND image_data.meta_key = "_wp_attached_file"')
cursor.execute(query)
posting_list = []
for (id, content, title, url, post_date, modified_date, meta_value, image) in cursor:
print("Post {} found. URL: {}".format(id, url))
meta_data = {}
keywords = []
image_url = wp_attachments_url_prefix + image
image_file = wp_attachments_prefix + image # 이미지 파일의 위치 찾기
# 1. Dominant raw color 를 추출합니다.
dominant_color = raw_color.get_dominant_rgb(image_file)
keywords.append(dominant_color)
# 3. flower classification 을 통해 추가 데이터를 추출해 냅니다.
# image_class, confidence = classifier.predict_class(title, image_url, class_names, model)
#if (confidence > 0.8):
# print(image_url + ' is most likely ' + image_class)
# keywords.append(image_class)
for n_gram in title.split():
if n_gram in wiki_kg:
print("found entry for " + n_gram+dominant_color)
meta_data = {**meta_data, **wiki_kg[n_gram]}
subspecies = maybeGetSubspecies(wiki_kg[n_gram])
if subspecies != None:
keywords.append(subspecies)
product = ProductPost(id, content, title, url,
post_date, modified_date, assumeShippingLocation(meta_value), image, meta_data, " ".join(keywords))
posting_list.append(product)
cursor.close()
cnx.close()
return posting_list
red 검색 결과
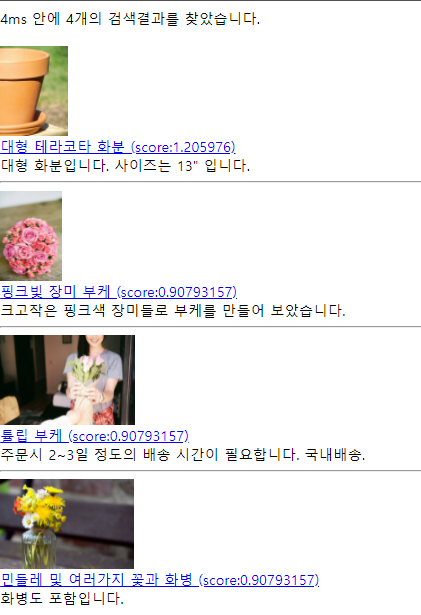
red 장미 검색 결과

이미지 색상 검색 실습2 : 이미지 classification
- 다음 실습으로는 우리가 이미지 처리의 꽃이라 할 수 있는 classification 을 이용해 이미지 처리에 정확도를 높이고, 우리가 검색엔진 기술과 어떻게 접목하는지 한 번 알아보자.
- cnn 을 이용해 이미지 레이블링 데이터를 사용해 정확도를 높일 것이다.
- tensorflow 가 꽃과 관련된 이미지 실습 데이터를 제공하기 떄문에 그것을 이용할 것이다.
pip3 install -q tf-nigthlyimport numpy as np
import os
import PIL
import tensorflow as tf
import ssl
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz" # 3000
train_epoch_level = 10 # cnn 이 몇 가지 레벨이 있는지, 레벨 자체는 실무적으로 봤을때, 10 ~ 20 정도면 매우 적당하다.
train_img_width = 180
train_img_height = 180
def build_flower_model():
ssl._create_default_https_context = ssl._create_unverified_context
data_dir = tf.keras.utils.get_file(
'flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("training image count: " + str(image_count))
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(train_img_height, train_img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(train_img_height, train_img_width),
batch_size=batch_size)
class_names = train_ds.class_names
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
num_classes = 5
model = Sequential([
layers.experimental.preprocessing.Rescaling(
1./255, input_shape=(train_img_height, train_img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True),
metrics=['accuracy'])
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=train_epoch_level
)
return class_names, model
def predict_class(name, url, class_names, model):
item_path = tf.keras.utils.get_file(name, origin=url)
img = keras.preprocessing.image.load_img(
item_path, target_size=(train_img_height, train_img_width)
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
return class_names[np.argmax(score)], np.max(score)
ingestor
import ast
import datetime
import hashlib
import json
import mysql.connector
import requests
import kg.kg_loader as kg_loader
import flower_classifier.tf_classifier as classifier
import flower_classifier.raw_color as raw_color
# SQL 에 연결하여 제품 페이지들을 추출하여 ProductPost array 로 돌려주는 함수입니다
def getPostings():
wp_attachments_prefix = '../www/wp-content/uploads/' # 데이터베이스에 있는 이미지들이 이러한 파일 로케이션에 있기 떄문에 파일 이름을 쉽게 받아주기 위해 이런 prefix 를 넣었다.
wp_attachments_url_prefix = 'http://localhost:8000/wp-content/uploads/' # 웹에서 찾을 떄, prefix
kg_source = 'kg/kowiki-20210701-pages-articles-multistream-extracted.xml'
wiki_kg = kg_loader.loadWikimedia(kg_source)
cnx = mysql.connector.connect(user='root',
password='my_secret_pw',
host='localhost',
port=9906,
database='flowermall')
cursor = cnx.cursor()
# 2. Flower model 을 train 합니다.
class_names, model = classifier.build_flower_model()
query = ('SELECT posts.ID AS id, posts.post_content AS content, posts.post_title AS title, posts.guid AS post_url, posts.post_date AS post_date, posts.post_modified AS modified_date, metadata.meta_value AS meta_value, image_data.meta_value AS image FROM wp_posts AS posts JOIN wp_postmeta AS image_metadata ON image_metadata.post_id = posts.ID JOIN wp_postmeta AS image_data ON image_data.post_id = image_metadata.meta_value JOIN wp_postmeta AS metadata ON metadata.post_id = posts.ID WHERE posts.post_status = "publish" AND posts.post_type = "product" AND metadata.meta_key = "_product_attributes" AND image_metadata.meta_key = "_thumbnail_id" AND image_data.meta_key = "_wp_attached_file"')
cursor.execute(query)
posting_list = []
for (id, content, title, url, post_date, modified_date, meta_value, image) in cursor:
print("Post {} found. URL: {}".format(id, url))
meta_data = {}
keywords = []
image_url = wp_attachments_url_prefix + image
image_file = wp_attachments_prefix + image # 이미지 파일의 위치 찾기
# 1. Dominant raw color 를 추출합니다.
dominant_color = raw_color.get_dominant_rgb(image_file)
keywords.append(dominant_color)
# 3. flower classification 을 통해 추가 데이터를 추출해 냅니다.
image_class, confidence = classifier.predict_class(title, image_url, class_names, model)
if (confidence > 0.8):
print(image_url + ' is most likely ' + image_class)
keywords.append(image_class)
for n_gram in title.split():
if n_gram in wiki_kg:
print("found entry for " + n_gram+dominant_color)
meta_data = {**meta_data, **wiki_kg[n_gram]}
subspecies = maybeGetSubspecies(wiki_kg[n_gram])
if subspecies != None:
keywords.append(subspecies)
product = ProductPost(id, content, title, url,
post_date, modified_date, assumeShippingLocation(meta_value), image, meta_data, " ".join(keywords))
posting_list.append(product)
cursor.close()
cnx.close()
return posting_list
p = getPostings()
postToElasticSearch(p)
- 결과: pink rose -> rose 라는 단어를 사진에서 추출해 핑크 장비 부케에 키워드 추가했다.
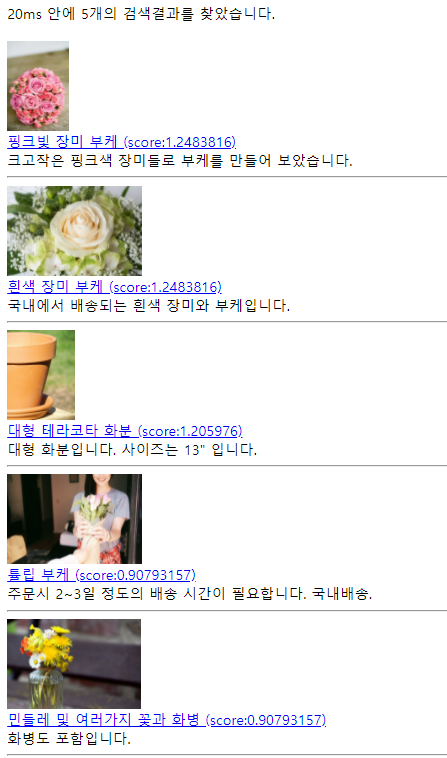
반응형
'SAS' 카테고리의 다른 글
| 패스트캠퍼스 엘라스틱서치 03. 지식 그래프(knowledge graph)를 활용해 검색 품질 향상하기 (0) | 2021.12.06 |
|---|---|
| 패스트캠퍼스 엘라스틱 서치 Part1. 검색엔진 기술의 개요 (0) | 2021.12.01 |
| sas 공부 이거로 하는중 (0) | 2021.11.05 |