
반응형
03. 지식 그래프(knowledge graph)를 활용해 검색 품질 향상하기
- 위키피디아 같은 지식 그래프를 이용해 키워드를 확장시켜봅시다.
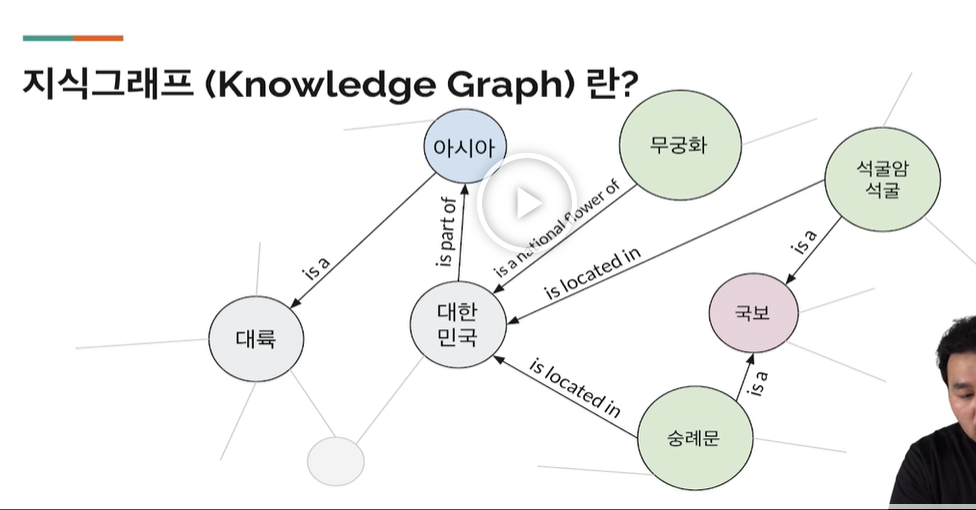
지식 그래프란
- SQL 과 달리, 지식을 그래프 형식으로 표현하여 새로운 정보의 추론과 여러가지 속성을 확장할 수 있는 새로운 종류의 그래프데이터베이스이다.
- 여기서 보시다싶이 여러가지 엔티티, 즉 아이디어 , 그리고 그 컨셉들의 릴레이션쉽을 이렇게 그래프로 나타내주는 지식 그래프라는 컨셉이다.
- 단순, SQL 로 이 관계들을 표현하려면 많은 테이블들, 그리고 무궁무진한 제한이 필요하겠지만, 이런 지식 그래프를 통해서 이런 엔티티를 하나하나 정리해주고, 이 엔티티 사이에 릴레이션을 정의해줌으로써, 매우 효과적인 데이터 스토어, 그리고 매우 impactful 한 inference 를 가져올 수 있습니다.
- 예) , 어느 대륙에 숭례문이 위치해 있는가?
- 숭례문 -> 대한민국 -> 아시아 -> 대륙 !
- 3 HOC 만에 답을 해결해줄 수 있다.
- 검색에서 찾을 수 없는 이러한 inference 를 통해 존재하지 않는 정보들을 이런, transitivity , 그렇게 파도타기처럼 다른 로드로드 로 파도를 탐으로써 지식을 가져올 수 있는 이런 데이터가 나올 수 있습니다.
- 예) , 어느 대륙에 숭례문이 위치해 있는가?
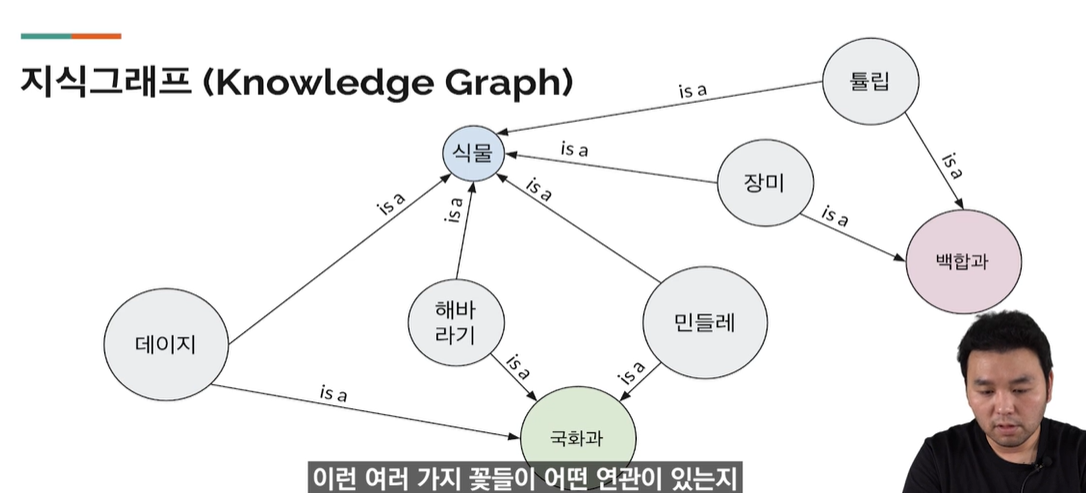
플라워몰에 지식 그래프를 연계 예( 얼개만 )
- 튤립, 장미 , 민들레, 해바라기, 데이지
- 백합과를 검색할 떄, 장미와 튤립이 나올 수 있도록
- 어디 DB 에 저장할까?
- sql 에 저장해도되지만, 코스트가 있다.
- 원초적으로 그리고, 자연적으로 더 빨리 , 엔티티 사이에 파도타기를 할 수 있게 전문화된 데이터베이스들이 있다.
- 예. Neo4j, RedisGraph.. 여러 실전에 투여되고 있는 그래프 데이터베이스가 있다.
지식 그래프 활용사례
- 친구관계를 표현하기 위해 페이스북에서는 그래프 데이터베이스를 이용하고 있다.
- 스마트 스피커: 아마존 알렉사
- 숭례문은 어느 대륙에 위치해? 같은 대답을 하기 위해서 지식 그래프를 이용
- 클로바는 현재 대답 못하네
- 숭례문은 어느 대륙에 위치해? 같은 대답을 하기 위해서 지식 그래프를 이용
- SNS : 친구 관계, 포스팅 우선순위
- 개인화된 교육 ㅣ 수학 컨셉을 설명하기 위한 관련 주제 연결 , 관련 토픽 복습 도움
- 날씨 예측 : 날씨 는 수백 요소의 조합체이다.
- 선거 공략
- 교통 정책
- 정부 오픈 데이터
- 반테러/보안
- 엔터테인먼트
- 금융
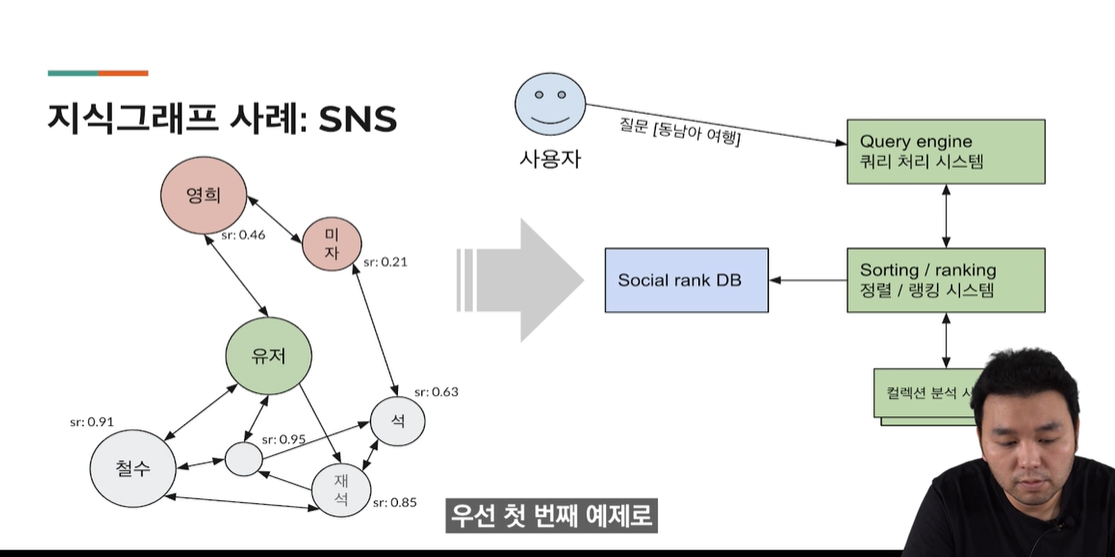
지식그래프의 사례 : SNS
- 유저가 "동남아 여행"이라는 질의를 던졌을떄, 2촌 3촌간의 관계의 지인들의 "동남아 여행"에 관련된 컨텐츠를 RELEVANT 한 순위대로 보여줘 유저네게 어떤 컨텐츠의 의미를 부여할 수 있다.
- 클러스터/클러스터링 = k means 또는 여러 클러스터링 알고리즘을 사용해 나타낼 수 있는 하나의 그룹핑을 만들어낸 것이다. 즉, 여러가지 커넥션들이 있지만, 이 커넥션들 사이에서 그 SUB GROUP 이 무엇인지, 그리고 이 SUB 그룹 사이에 어떠한 커넥션들이 있는지, 이러한 것들을 나타낼 수 있는 방법을 클러스터링이라고 한다.
- 이러한 클러스터링을 이용해 , 영희와 미자가 한 그루핑이고, 철수 재석 석이가 비슷한 클러스터링이다.
- 그래서 만약, 동남아 여행에 관해 "석"이 포스팅을 올리는 경우,, 유저 간에 1대1로 연결되어있지 않지만, 이 유저와 절친인 철수, 그리고 재석과 깊은 연관을 가지고 있기 떄문에 이 스코어를 더 높게 줄 수 있습니다.
- 그래서 여기 우리 SR 소셜랭크라는 개념을 우리가 부여했다. 이러면, 랭크가 좀 더 높을 수 있다.
- 반면, 영희와 유저도 직접적으로 관련되어있는 반면, 스코어링이 낮아 유저와 미자는 큰 연관관계가 없다. (= 큰 소셜 랭크가 부여될 필요가 없다. )
- 소셜랭크는 지금까지 소셜 네트워크를 사용하면서 여러가지 인터렉션들, 그리고 포스팅, 서로 코멘트를 달아주는 형식 등을 봄으로써 알아낼 수 있는 이런 시그널이 된다.
- 따라서, 미자와 석이 동시에 동남아 포스팅을 올리면 석이 상단에 올라와야한다.
- 그래서 만약, 동남아 여행에 관해 "석"이 포스팅을 올리는 경우,, 유저 간에 1대1로 연결되어있지 않지만, 이 유저와 절친인 철수, 그리고 재석과 깊은 연관을 가지고 있기 떄문에 이 스코어를 더 높게 줄 수 있습니다.
- 이러한 클러스터링을 이용해 , 영희와 미자가 한 그루핑이고, 철수 재석 석이가 비슷한 클러스터링이다.
- 마치 점수처럼 낮은 점수는 relevancy 가 낮고, 높은 점수는 relevancy 가 더 높다. 높은 점수는 상위, relevant 랭킹0한다.
- 소셜랭킹 DB = 지식 그래프가 있는 경우, 랭킹에 지식 그래프가 이용될 수 있다.
지식 그래프 사례 : 개인화된 교육

위키미디어 데이터를 사용해 지식 그래프 구현하기
위키미디아 데이터를 사용하여 관련 키워드 확장하기
- 위키피디아에서 "과" 정보를 추출해 키워드에 추가해봅시다.
create_index2.pyingestor2.py
- 관련라이브러리
mwparserfromhell이라는 라이브러리- 위키미디어의 데이터가 쉽게 parser 해주는 하나의 모듈이다.
- 위키미디어 파일 형태의 파일인 어느 파일을 열게되면 이것을 이 라이브러리를 통해 parser 할 수 있게 해준다.
# ingestor/kg/kg_loader.py
import mwparserfromhell
import re
import xml.etree.ElementTree as etree
def loadWikimedia(source_file):
tree = etree.parse(source_file)
root = tree.getroot()
namespace = getNamspace(root.tag)
kg = {}
for page in root.findall('./' + namespace + 'page'):
title = page.find(namespace + 'title').text
page_content = page.findall(
'./' + namespace + 'revision/' + namespace + 'text')
entry = {}
if len(page_content) > 0:
wikicode = mwparserfromhell.parse(page_content[0].text)
templates = wikicode.filter_templates()
for template in templates:
#print(template.name)
for param in template.params:
value = stripWikilinksForText(str(param.value)).strip()
if len(value) > 0:
entry[str(param.name).strip()] = value
kg[title] = entry
return kg
# 위키미디아 스타일 링크에서 텍스트만을 추출하는 helper function 입니다.
def stripWikilinksForText(wikilink):
return re.sub(r'\[\[(.+?)\|.+?\]\]', r'\1', wikilink).replace('[[', '').replace(']]', '')
# XML 의 namespace 를 찾아 돌려줍니다.
def getNamspace(tag):
return '{' + tag.split('}')[0].strip('{') + '}'
title 의 ngram 에서 wiki 에서 찾을시, data 를 추가해준다.
- 각 단어마다 위키미디아에 관련 정보를 찾아봅니다.title 을 공백별로 잘라서 위키미디어에서 관련 정보를 찾는다.
예 : 흰색 장미 부케 -> 흰색 / 장미 / 부케 - gram: 우리가 이런 식으로 타이틀 또는 이런 쿼리를 나눌 떄, 각 단어를 보고 gram 이라 한다.
하나의 그 subtext 그리고 text가 여러 개 있을 수 있기 떄문에 ngram 이라 부른다.
import ast
import datetime
import hashlib
import json
import mysql.connector
import requests
import kg.kg_loader as kg_loader
# SQL 에 연결하여 제품 페이지들을 추출하여 ProductPost array 로 돌려주는 함수입니다
def getPostings():
kg_source = 'kg/kowiki-20210701-pages-articles-multistream-extracted.xml'
wiki_kg = kg_loader.loadWikimedia(kg_source)
cnx = mysql.connector.connect(user='root',
password='my_secret_pw',
host='localhost',
port=9906,
database='flowermall')
cursor = cnx.cursor()
query = ('SELECT posts.ID AS id, posts.post_content AS content, posts.post_title AS title, posts.guid AS post_url, posts.post_date AS post_date, posts.post_modified AS modified_date, metadata.meta_value AS meta_value, image_data.meta_value AS image FROM wp_posts AS posts JOIN wp_postmeta AS image_metadata ON image_metadata.post_id = posts.ID JOIN wp_postmeta AS image_data ON image_data.post_id = image_metadata.meta_value JOIN wp_postmeta AS metadata ON metadata.post_id = posts.ID WHERE posts.post_status = "publish" AND posts.post_type = "product" AND metadata.meta_key = "_product_attributes" AND image_metadata.meta_key = "_thumbnail_id" AND image_data.meta_key = "_wp_attached_file"')
cursor.execute(query)
posting_list = []
for (id, content, title, url, post_date, modified_date, meta_value, image) in cursor:
print("Post {} found. URL: {}".format(id, url))
meta_data = {}
keywords = []
"""
# 1. 각 단어마다 위키미디아에 관련 정보를 찾아봅니다.
# title 을 공백별로 잘라서 위키미디어에서 관련 정보를 찾는다.
예 : 흰색 장미 부케
-> 흰색 / 장미 / 부케
gram: 우리가 이런 식으로 타이틀 또는 이런 쿼리를 나눌 떄, 각 단어를 보고 gram 이라 한다.
하나의 그 subtext 그리고 text가 여러 개 있을 수 있기 떄문에 ngram 이라 부른다.
"""
for n_gram in title.split():
if n_gram in wiki_kg:
print("found entry for " + n_gram)
meta_data = {**meta_data, **wiki_kg[n_gram]}
subspecies = maybeGetSubspecies(wiki_kg[n_gram])
if subspecies != None:
keywords.append(subspecies)
product = ProductPost(id, content, title, url,
post_date, modified_date, assumeShippingLocation(meta_value), image, meta_data, " ".join(keywords))
posting_list.append(product)
cursor.close()
cnx.close()
return posting_list
# 2. 위키미디아 데이타에 특정한 attribute을 추출합니다.
# Subspecies field 가 해당 wiki data 에 존재하면 돌려줍니다. 아니면 None 을 돌려줍니다
def maybeGetSubspecies(wiki_page):
sub_species_key = u'과'
if sub_species_key in wiki_page:
return wiki_page[sub_species_key]
return None
(venv) kil@DESKTOP-LCIE51D:~/es_example/es/es_tutorial/es/ingestor$ python tools/check_es_index.py
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":7,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"products","_type":"_doc","_id":"90063200dc4ce5dc4271f7bb1b9750e481a5c8f6","_score":1.0,"_source":{
"content": "\ub300\ud615 \ud654\ubd84\uc785\ub2c8\ub2e4. \uc0ac\uc774\uc988\ub294 13\" \uc785\ub2c8\ub2e4.",
"id": 10,
"image_file": "2021/07/terra-cotta-planter.jpg",
"keywords": "",
"meta_data": {
"1": "2",
"16\uc9c4\uc218\uac12": "B66655",
"2": "terracotta, terra cotta, terra-cotta",
"B": "71",
"b": "85",
"c": "0",
"g": "102",
"h": "11",
"k": "30",
"m": "57",
"r": "182",
"s": "53",
"y": "52",
"\uc81c\ubaa9": "\ud14c\ub77c\ucf54\ud0c0"
},
"modified_date": "2021-07-02T15:28:15",
"post_date": "2021-07-01T18:55:54",
"shipped_from": "\ud574\uc678",
"title": "\ub300\ud615 \ud14c\ub77c\ucf54\ud0c0 \ud654\ubd84",
"url": "http://localhost:8000/?post_type=product&p=10"
}},{"_index":"products","_type":"_doc","_id":"c483a0fd93699a19550df78d12a37245ba8b5079","_score":1.0,"_source":{
"content": "\ud558\uc580 \uaf43\ubcd1, 3\" \ud55c\uac1c\uc640 \ud574\ubc14\ub77c\uae30 2\uc1a1\uc774\uac00 \ubc30\uc1a1\ub429\ub2c8\ub2e4.",
"id": 14,
"image_file": "2021/07/sunflower.jpg",
"keywords": "\uad6d\ud654\uacfc",
"meta_data": {
"1": "\ud574\ubc14\ub77c\uae30 \uc528",
"2": "Helianthus \ub610\ub294 sunflower",
"ISBN": "9788993905755",
"\uacc4": "\uc2dd\ubb3c",
"\uacfc": "\uad6d\ud654\uacfc",
"\uadf8\ub9bc": "Sunflower sky backdrop.jpg",
"\uae30\ud0c0": "\uad6c\uacc4\uc6d0 \uc62e\uae40",
"\ub0a0\uc9dc": "2011-11-01",
"\ubaa9": "\uad6d\ud654\ubaa9",
"\ubbf8\ubd84\ub958_\uac15": "\uc9c4\uc815\uc30d\ub5a1\uc78e\uc2dd\ubb3c",
"\ubbf8\ubd84\ub958_\ubaa9": "\uad6d\ud654\uad70",
"\ubbf8\ubd84\ub958_\ubb38": "\uc18d\uc528\uc2dd\ubb3c",
"\uc0c9": "\uc2dd\ubb3c",
"\uc131": "Nabhan",
"\uc18d": "\ud574\ubc14\ub77c\uae30\uc18d",
"\uc544\uacfc": "\uad6d\ud654\uc544\uacfc",
"\uc774\ub984": "Gary Paul",
"\uc800\uc790": "\uc560\ub108 \ud30c\ubcf4\ub974\ub4dc",
"\uc81c\ubaa9": "2\ucc9c\ub144 \uc2dd\ubb3c \ud0d0\uad6c\uc758 \uc5ed\uc0ac : \uace0\ub300 \ud76c\uadc0 \ud544\uc0ac\ubcf8\uc5d0\uc11c \uadfc\ub300 \uc2dd\ubb3c\ub3c4\uac10\uae4c\uc9c0 \uc2dd\ubb3c \uc778\ubb38\ud559\uc758 \ubaa8\ub4e0 \uac83",
"\uc871": "\ud574\ubc14\ub77c\uae30\uc871",
"\uc885": "'''\ud574\ubc14\ub77c\uae30''' (''H. annuus'')",
"\ucd9c\ud310\uc0ac": "\uae00\ud56d\uc544\ub9ac",
"\ud559\uba85": "''Helianthus annuus''",
"\ud559\uba85_\uba85\uba85": "\uce7c \ud3f0 \ub9b0\ub124, 1758"
},
"modified_date": "2021-07-02T15:27:56",
"post_date": "2021-07-01T19:01:43",
"shipped_from": "\ud574\uc678",
"title": "\uaf43\ubcd1\uc5d0 \ub2f4\uae34 \ud574\ubc14\ub77c\uae30 2\uc1a1\uc774",
"url": "http://localhost:8000/?post_type=product&p=14"
}},- "국화과" 검색 결과
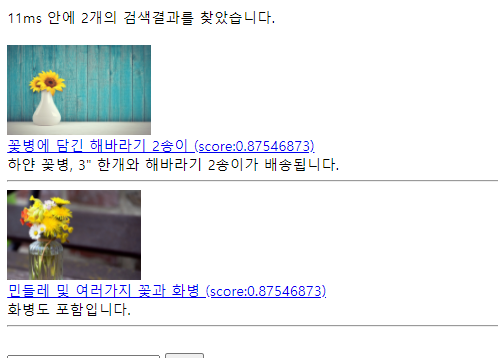
- 이것은 지식그래프를 사용한 적절한 실전사례는 되지 않는다. 왜냐면 이렇게 키워드를 추가함으로써 우리가 effiecient 한 graph traverse 를 할 수 없기 떄문이다. 그렇기 떄문에 실전에서는 거의 대부분 인덱스 사이드에서 색인하는 과정에서 키워드를 추가하지 않고 , 우리가 쿼리, 즉, 해바라기 라는 쿼리가 들어왔을 때, 해바라기의 과가 국화과라는 것을 우리가 알기때문에 , 국화과라는 키워드를 그냥 추가해서 찾아볼 수 있게 도와준다.
- 아니면 국화과라는 키워드가 왔을 때, 국화과인 해바라기, 그리고 민들레 이런 것을 키워드에 추가해서 색인을 찾아보는 방식으로 실전에서는 진행한다.
- 하지만, 우리 예제에서는 인덱싱 사이드에서 어떻게 위키피디아 페이지를 사용해 이 속성을 확정할 수 있는지 알아 보았습니다.
정리
우리는 위키피디아나 이런 그래프를 이용해 색인 과정에서 이렇게 확장성을 늘릴 수 있고, 키워드에 관련 검색어를 이렇게 늘릴 수 있습니다. 또한, 실전에서는 이것이 물론 색인뿐만 아니라, 쿼리 과정에서 쿼리를 확장하는데 사용이 됩니다. 그래서 내가 '국화과"라는 단어를 검색했을 떄, 국화과에 관련된 해바라기, 또는 민들레를 쿼리에 추가해 , 국화과 또는 장미 이렇게 쿼리를 확장하는대로 사용할 수 있다.
반응형
'SAS' 카테고리의 다른 글
| 패스트 캠퍼스 엘라스틱서치 PART04. 부속 프로세싱 - 이미지 처리 기술과 검색 기술의 융합 (0) | 2021.12.06 |
|---|---|
| 패스트캠퍼스 엘라스틱 서치 Part1. 검색엔진 기술의 개요 (0) | 2021.12.01 |
| sas 공부 이거로 하는중 (0) | 2021.11.05 |