
반응형
Part1. 검색엔진 기술의 개요
01-01. 강의 개요
- 검색 엔진 기술의 개요
- 엘라스틱 서치를 사용해 간단한 쇼핑몰 검색 기능 만들기(실습 위주)
- 지식 그래프의 개요(실습 포함)
- 이미지 처리를 활용해 검색 결과를 향상시키기(실습위주)
- 검색랭킹(실습 포함) : 방대한 빅 데이터에서 검색 결과를 돌려줄 때, 어떠한 결과가 더 연관성(relevance)한지, 더 먼저 나와야하는지 , 사용자의 주의를 끄는 것(attention)이 더 필요한 것인지 이것을 찾아 주는 것이 검색 랭킹이다. 또한, relevance 라고 부르기도 한다.
- 검색 기술에 대한 기본 지식
- 검색엔진 중급 클래스인 엘라스틱서치를 활용해 고급 검색 엔진 만들기 강의
- 이 강의를 통해 검색 엔진 기술이 무엇인지, 그리고 검색엔진들은 어떤 아키텍처로 디자인 되어 있는지
- 다른 기술과 어떠한 장점과 단점을 가지고 있는지
- 엘라스틱서치를 활용해 고급 검색엔진 기능들을 추가하는 실습
- 검색엔진 기술들을 배우고, 검색 엔진이 어떤 동기에서 시작되었는지,
- 그리고, 검색 엔진의 기본 아키텍처 MySQL 이나 NoSQL 과 비교해 검색엔진이 어떤 차이가 있는지
- 실리콘밸리에서 검색엔진 기술 등을 활용해 어떤 기능들을 구현하고 있는지 배워볼 예정
what we will learn
- 검색 기술에 대한 기본 지식
- 엘라스틱서치를 활용한 검색 시스템 구축
- 지식 그래프, 부속처리 기술들을 사용한 고급 검색 기술 활용법
- 검색 랭킹의 기본 지식, 검색 결과의 개인화에 대한 개요
- 예제를 통한 위 기술들에 대한 기본적인 실습
what should i take this course
- 빅데이터의 경쟁력은 데이터를 최대한 빠르고 효율적으로 정리해주는 기술이다.
- 현존하는 데이터 규모는 현재도 폭발적인 성장을 하고 있다.
- 빅데이터를 다룰 줄 아는 자가 빅데이터의 패러다임을 이끄는 기업의 핵심 전문가가 된다.
01-03. 검색엔진 기술의 개요
개요
- 검색엔진 기술이란?
- SQL, NoSQL 비교
- 검색엔진 기술의 기본 아키텍처
- 실리콘밸리에 검색 기술활용사례
검색엔진 시스템이란
- 컴퓨터 시스템에 저장된 정보를 찾아주는 것을 도와주도록 설계된 정보 검색 시스템(출처ㅣ 위키피디아)
검색 시스템들의 사례
- 오프라인
- 파일검색, 데스크탑 검색(마이크로소프트 코타나)
- 검색 서비스
- 웹 검색, 이미지 검색, 비디오, 오디오 검색 등등
- 인터페이스형
- 인공지능 개인비서 : 아마존 알렉사, 삼성 빅스비 등
- 지도형 : 카카오맵, 배달앱등
- 추론형
- 부동산 : zillow , redfin
- 여러 데이터들을 종합하여 추론을 inference as a service 방식으로 제공해주는 서비스도 있다.
01-04. SQL 과 검색 엔진 비교
요약 : scale, speed, and usefulness
| SQL | 검색엔진 |
|---|---|
| * transaction 을 위해 제작된 데이터 베이스 * acid라는 property를 제공해주는 큰 장점을 가지고 있습니다. * acid : atomic, consistent, isolated, and durable 의 줄임말이다. * acid 는 모든 트랜잭션이 commit 이 되면 이뤄졌다는 것이 확실해지고, 모든것이 확실해졌다는 말의 줄임말 | *검색엔진은 ACID 속성을 제공해주지 않고 있다.검색엔진은 결과가 stale 해질 수 있고, 없는 결과가 나타날 수 있고, 데이터가 바뀌어도 반영되는데 시간이 걸릴 수 있습니다. |
| ACIDic, even in read replica | Queries returned in near constant time ~O(1) |
| Slow down as data size increases O(log N) | Data can expand almost infinitely |
| Realtime up-to-date data | data can be stale |
| Advanced search features/ rankinf very difficult | |
| linear increase in traffic can cause exponential decay in service speed | Traffic increase is unrelated to the system itself, serving systems can grow linearly with the traffic |
- sql 데이터베이스들은 구체적으로 b-tree 나 linear scan 들을 사용해 결국엔 데이터사이즈가 커지면 커질 수록 속도가 줄어드는 이런 단점을 가지고 있다.
- 반대로 검색 엔진은 데이터 사이즈가 커지더라도 전혀 상관없이 결과를 거의 커스텀 타임에 돌려줄 수 있는 매우 강력한 장점을 가지고 있다.
- 시간복잡도가 sql 엔진은 O(n) 또는 O(log N) 을 가지는 현상이 있는데, 검색엔진은 o(1)을 가진 혁기적인 데이터베이스라 볼 수 있다.
- sql 은 realtime 데이터를 제공할 수 있는 장점을 가지고 있다. sql 에 저장된 데이터는 realtime 으로 바로 반영이 되고 바로 모든 subscribe 들이 볼 수 있는 이러한 데이터인 반면에
- 검색엔진은 데이터가 추가되고 인덱싱되고, 그리고 서빙되는데 꽤 큰 시간이 필요하다.
- sql 로 제공된 검색 결과들은 고급 검색결과, 랭킹 등을 도입하기 매우 힘들다. sql 자체가 transactional nature 를 위해 만들어진 데이터베이스이기 때문에 이 위에 고급 텍스트 manipulation , 오디오 이미지 프로세싱 이런 것들을 추가하기에 매우 벅차다.
- 반면 검색엔진은, 무제한 advanced search feature를 추가할 수 있는 장점이 있다.
- sql 는 serving traffic 이 늘어나면 늘어날 수록 serving speed가 기하급수적으로 감소할 수 있다. 즉, 사용자가 Linearly 증가할 수록 service는 exponentially 더 비싼 코스트를 요구하게 된다.
- 반면에 검색 엔진은 트래픽이 늘어나도, 부하 속도는 일정적으로 유지된다.
01-05. 검색엔진 색인 개요
- 검색엔진 기술 핵심을 한 마디로 축출한다면, 인덱싱 = 색인을 꼽을 수 있다.
01-06. 검색엔진 아키텍처

- 빅데이터
- 수집, 주석 시스템
- 인터넷 동영상 사이트 그리고 음악 사이트 같은데서 들어오는 raw 데이터를 추가해주고 거기에 추가 메타데이터 추가해주는 역할
- 주석 데이터 저장소
- 색인 시스템
- 데이터 읽고 색인 생성하는 과정
- 여러 단어들과 그리고 annotation 을 찾아 색인을 만든다.
- 색인들
- 인덱싱 또는 색인시스템들이 추출해낸 결과는 일종의 색인 또는 색인들로 만들어져 저장된다.
- 이렇게 해서 생성된 색인들은 서빙 시스템들이 사용하기 편하게 분리돼 저장할 수 있다
- 컬렉션 분석 시스템들
- 색인들을 이용해 쿼리 또는 사용자의 질문들을 서빙하게 된다.
- 그리하여 사용자가 자연어로 질문 또는 쿼리를 요청하면 오른쪽에 보이는 쿼리 엔진, 또는 쿼리 처리 시스템들이 이러한 자연어를 서빙시스템이 이해하기 편하게 다시 재분석해주고 이러한 쿼리들을 소팅 또는 랭킹 시스템이 여러가지 컬렉션 애널리시스템에 보내게 됩니다. 그리하여 이런 컬렉션 애널리시스, 또는 분석 시스템들은 이렇게 분산된 색인들 사이에서 필요한 정보들을 추출해 소팅 , 또는 랭킹 시스템에 돌려주게 되고, 소팅 랭킹 시스템은 여기서 돌아온 결과들을 종합하고 머지하여 제일 유용하고, 제일 효과적인 결과를 돌려주게됩니다. 이 돌려진 결과물들은 쿼리 처리 시스템이 다시 한번 사용자에게 보기 편한 방식으로 리턴하게 됩니다.
- 정렬 시스템
- 쿼리 처리 시스템
01-07. NoSQL 과 검색엔진

- 그러면 하나의 쿼리가 정확히 서빙 시스템에 어떻게 전달되고 이 결과가 다시 돌아오는지 자세히 봅시다.
- 색인들은 아까 언급된 topological sorting 과 같은 방식으로 정렬이 되어있기 때문에 소팅 랭킹 시스템을 정확히 어떤 컬렉션 분석 시스템에 이쿼리를 보내야 할지 미리 알고 있을 수 있습니다. => 전체적인 시스템 부하를 줄일 수 있다.
- 그래서 fox 와 brown 이라는 단어를 가지고 있는 컬렉션 분석 시스템들은 이 단어들을 가지고 있는 문서들을
다시 소팅 랭킹 시스템에 보내줄 수 있고, 이렇게 보내진 결과는 소팅, 랭킹 시스템이 하나로 뭉쳐서 다시 쿼리 처리 시스템에 보낼 수 있게 됩니다. - 이렇게 돌아온 결과들은 소팅 랭킹 시스템들이 통합한 결과로 뭉쳐 merge 하여 뭐리 엔진 처리 시스템에 돌려주게 됩니다.
- 이렇게 돌려진 결과는 사용자가 보기 편하게 다시 돌려지겠죠.
자 그러면 여기서 여러가지 질문들을 할 수 있겠죠. 예를들어 brown fox 가 브랜드 이름인지, 브랜드 이름이라면, brown 과 fox 라는 단어가 따로 떨어져 있으면 안되겠죠. 그래서 brown 이라는 단어와 fox 라는 단어가 한 문장에 가까우면 가까울 수록 더 중요한 문서가 될 수 있고, 또한, 그러한 경우라면, fox가 brown 보다 먼저오는 문장은 별로 중요해지지 않겠죠.
그래서 이런 문자들을 토대로 정렬해주는 것을 랭킹 섹션에서 배우게 될 것입니다.
NoSQL DB들과 어떤 것이 다른가요?
- 자 그러면 검색엔진 시스템들이 NoSQL 데이터베이스들과 어떻게 다른가요?
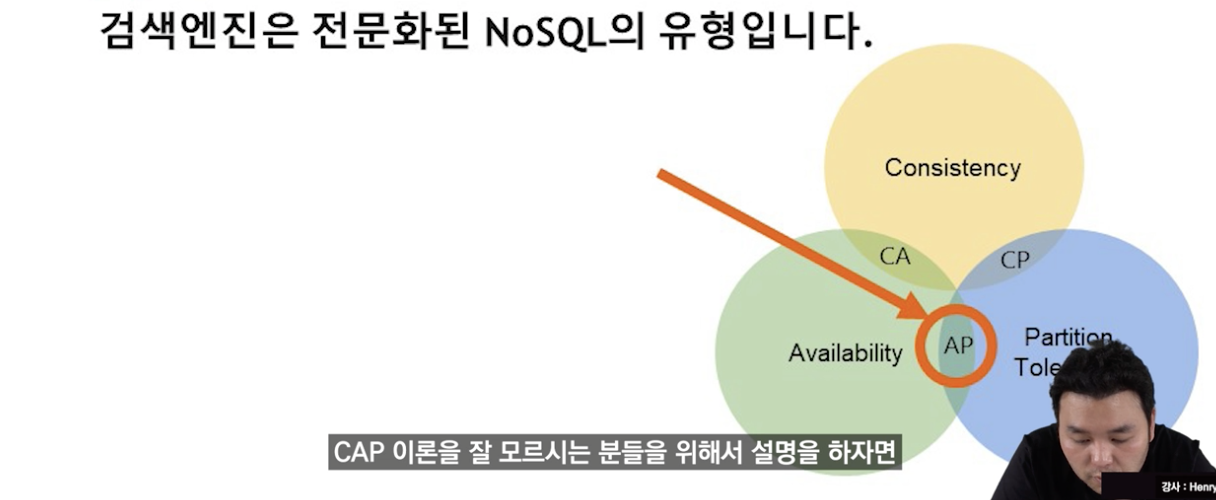
- NosqL 은 sql 과 달리 acid property를 제공하지 않고 보통은 더 좋은 consistnecy 아니면 더 좋은 partition tolerance 아니면 더 좋은 availability 를 제공해주는 새로운 종류의 데이터 서비스들
- cap 이론
- 현존하는 거의 모든 , 모든 데이터를 저장하는 매체들은 이 세가지 중 두 가지만을 추구할 수 있다는 이론이다.
- 예를들어 sql 은 consistency를 추구하는 데이터베이스이다. 반면에, 검색엔진 같은 서비스들은 availability 그리고 partition tolerance 를 축으로 하는 서비스이다. = consistency 를 버렸다. 즉, 검색엔진 색인에서는 만약에 하나의 문서가 변경됐을때, 색인이 변경되는데 시간이 걸리고, 그 사이에 consistency 가 추구되지 않을 수 있습니다.
01-08 검색엔진의 실리콘밸리 사례
- Quora
- 자연어, 관련 검색
- 여러 사람이 자신의 질문을 올리고, 그것을 답해주는 지식인 서비스
- 내가 검색하는 질의에 자신의 질문 뿐만 아니라, 질문에 있는 중요한 단어들을 축출하여 의미있는 질문의 답들을 볼 수 있는 이러한 인터페이스를 제공하고 있다.
- pinterest
- 이미지 검색 서비스
- 글자 뿐만 아니라, 이미지에 있는 여러 요소들을 사용하여 이미지 검색을 도와주고 있다.
- soundhound
- 음원 검색
- 사용자가 스마트폰으로 자기가 듣고 있는 음악을 녹음하면 이 음악이 무엇인지 찾아주는 서비스 제공
- 음악 소리들도 주석화처리를 통해 검색 기술이 손쉽게 찾아주는 놀라운 효과를 볼 수 있다.
- Palantir
- data insight
- 여러가지 데이터들을 종합하여 사용자들이 보고 추론 내리기 편한 인터페이스들을 제공하고 있습니다.
- 23andme
- dna 검색
- 여러가지 데이터들을 종합하여 사용자들이 보고 추론을 dna 에 적용
- Dna 분석 결과를 토대로 나와 dna 가 가장 일치하는 사람을 찾아주어 실종된 미아, 그리고 잊고 있던 자신의 혈통을 찾아주는 서비스
Part2. ElasticSearch 로 간단한 쇼핑몰 검색 기능 만들기
02-01. 엘라스틱 서치 개요
- 엘라스틱 서치는 인덱싱, 컬렉션 애널리시스, 그리고 소팅과 랭킹 섹션에 포함되는 기능을 처리하는 시스템이라 볼 수 있습니다.
- 엘라스틱서치와더불어 ingestion annotaion 을 도와주는 로그스태시(logstash), 쿼리처리를 도와주는 키바나(kibana)가 함께 사용되는 경우가 많다.
- 이 세 가지 제품을 통합하여 ELK 라는 Stack 으로 사용되고 있다.
- 로그스태시 : ingestion 과 annotation을 필요한 여러가지 메타 데이터 추출, 그리고 injestion 파이프라인에 들어가는 많은 데이터 소스들의 커넥션을 도와주는 기능들을 가지고 있습니다.
- 키바나 (Kibana) 는 쿼리 처리에 도움이 되는 인터페이스를 그리고 인터페이스를 확장할 수 잇는 이런 도구들을 추구하고 있습니다.
- 엘라스틱은 이 녹색섹션에서 보시다 싶이 색인, 그리고 색인을 생성하고, collection analysis, 소팅 랭킹 그리고 기본적인 쿼리를 도와주는 기능을 첨부하고 있습니다.
- 또한, 구체적으로 엘라스틱 서치는 apache foundation 이 제공하고 있는 LUCENE 라는 인덱싱 서비스를 사용하고 있습니다.
- 이 인덱싱 서비스 위에서 색인 생성 시스템이 인덱싱 서비스 위에 색인 생성 시스템, 그리고 소팅 , 랭킹, 애널리시스 서비스를 덧붙인 것이 엘라스틱 서치라 볼 수 있습니다.

- 이 인덱싱 서비스 위에서 색인 생성 시스템이 인덱싱 서비스 위에 색인 생성 시스템, 그리고 소팅 , 랭킹, 애널리시스 서비스를 덧붙인 것이 엘라스틱 서치라 볼 수 있습니다.
02-02. 플라워몰에 검색 기능 추가하기
- 엘라스틱서치에 대한 컨셉이 들어가게 되는데, 엘라스틱서치는 인덱스 또는 색인 하나만 서빙하는 것이 아니라 여러 가지 색인을 따로 만들어 제공할 수 있게 디자인되어있다. 그렇기 때문에 각 색인을 만들떄마다 인덱스를 만드는 과정이 필요하다.
인덱스에 대한 설명
- 색인 만드는 api
- RESR 를 어떤 방식으로 만들 수 있는지 나온다.
- put, post 를 이용해 새로운 인덱스를 만들 수 있다.
- index는 TARGET 이라는 이름으로 만들 수 있다.
- put, post 를 이용해 새로운 인덱스를 만들 수 있다.
- https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
- RESR 를 어떤 방식으로 만들 수 있는지 나온다.
색인 생성
- 엘라스틱 서치는 여러 인덱싱을 제공해주기 때문에 인덱싱을 하나하나 만들어야한다. 인덱스의 이름에 맞춰 문서가 따로 정렬된다.
# ingestor/create_index1.py
import requests
import json
url = "http://localhost:9200/products" # 엘라스틱 서치 주소
payload = json.dumps({
"settings": {
"index": {
"number_of_shards": 1, # 인덱스, 색인을 나누는 분산 숫자, 1인 경우 분산하지 않고 모든 인덱스를 하나에 저장하기 위해 만듬.
# number_of_shards 가 100 ,number_of_replicas 가 10 인 경우 = 색인이 100개로 나눠진다.
# 모든 100개의 샤드가 레플레카를 10개씩 가지게 된다. = 총 1000개의 서빙 인덱스가 생기는 것
# = 스케일링을 위해 필요한 요소이다.
"number_of_replicas": 1
# replica 는 AVAILABILITY 를 위해 존재하는 것이다.
# SHARD 는 역시 PERFORMANCE 를 위해 존재하는 것이다.
# 더 빨리 병행하도록 로드밸런싱을 하기 위해 존재하는 것이다.
},
"analysis": {
"analyzer": {
"analyzer-name": {
"type": "custom",
"tokenizer": "keyword", # 토큰 키워드 방식
"filter": "lowercase" # 들어오는 키워드들을 lowercase
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"content": {
"type": "text"
},
"title": {
"type": "text"
},
"url": {
"type": "text"
},
"image_file": {
"type": "text"
},
"post_date": {
"type": "date"
},
"modified_date": {
"type": "date"
},
"shipped_from": {
"type": "text"
}
}
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("PUT", url, headers=headers, data=payload)
print(response.text)ES 인덱스 스키마 확인
# ingestor/tools/get_es_schema.py
import requests
url = "http://localhost:9200/products"
payload = ""
headers = {}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)ES 인덱스 스키마 지우기
# ingestor/tools/delete_index.py
import requests
url = "http://localhost:9200/products"
payload = ""
headers = {}
response = requests.request("DELETE", url, headers=headers, data=payload)
# PRODUCTS 라는 인덱스 지우기
print(response.text)인덱스에 데이터 추가하기
자 이제 우리가 생성한 이 products라는 인덱스의 쇼핑데이터들을 injest 하는 injestor 라는 코드를 돌려보겠습니다.
# ingestor/ingestor1.py
p = getPostings()
postToElasticSearch(p)- ingestor1.py 에서 getPostings 라는 function 이 있습니다.
- SQL 에 연결하여 제품 페이지들을 추출하여 ProductPost array 로 돌려주는 함수입니다
- ingestion 을 대신하는 함수
# ingestor/ingestor1.py
# SQL 에 연결하여 제품 페이지들을 추출하여 ProductPost array 로 돌려주는 함수입니다
def getPostings():
cnx = mysql.connector.connect(user='root',
password='my_secret_pw',
host='localhost',
port=9906,
database='flowermall')
cursor = cnx.cursor()
query = ('SELECT posts.ID AS id, posts.post_content AS content, posts.post_title AS title, posts.guid AS post_url, posts.post_date AS post_date, posts.post_modified AS modified_date, metadata.meta_value AS meta_value, image_data.meta_value AS image FROM wp_posts AS posts JOIN wp_postmeta AS image_metadata ON image_metadata.post_id = posts.ID JOIN wp_postmeta AS image_data ON image_data.post_id = image_metadata.meta_value JOIN wp_postmeta AS metadata ON metadata.post_id = posts.ID WHERE posts.post_status = "publish" AND posts.post_type = "product" AND metadata.meta_key = "_product_attributes" AND image_metadata.meta_key = "_thumbnail_id" AND image_data.meta_key = "_wp_attached_file"')
cursor.execute(query)
posting_list = []
for (id, content, title, url, post_date, modified_date, meta_value, image) in cursor:
print("Post {} found. URL: {}".format(id, url))
product = ProductPost(id, content, title, url,
post_date, modified_date, assumeShippingLocation(meta_value), image)
posting_list.append(product)
cursor.close()
cnx.close()
return posting_list# 아주 naive 한 출고지 extraction subroutine
# 간단한 처리를 해서 넣어줌을 강조
def assumeShippingLocation(raw_php_array):
if u'국내' in raw_php_array:
return '국내'
return '해외'- 이 POSTING 들을 엘라스틱서치에 색인을 보내는 함수가 필요하다
help function
엘라스틱서치에서 사용될 문서의 고유 아이디를 생성
# ingestor/ingestor1.py
# 우리가 고유 문서에대한 특정 id 를 찾아서 이 ID 를 통해 중복이되는 것을 막기 위해 이렇게 생성하고 있다. :`getUniqueIndexId`
# 엘라스틱서치에서 사용될 문서의 고유 아이디를 생성합니다.
def getUniqueIndexId(url):
return hashlib.sha1(url.encode('utf-8')).hexdigest()색인 도큐먼트
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
- 문서를 색인화할 수 있는 이런 API들이 제공되고 있다.
- target : 인덱스 이름 제공
- _doc : 내가 문서를 색인하고 싶다.
- post : 엘라스틱서치가 이 문서에 대한 고유 id를 직접 만들 수 있고, POST 를 사용하지 않는 경우, put 을 사용해 직접 사용자가 id 를 제공할 수 있게 되어있다.
- 우리 예제의 경우, 우리가 직접 ID 를 생성한다.
- 그 이유는 우리가 고유 문서에대한 특정 id 를 찾아서 이 ID 를 통해 중복이되는 것을 막기 위해 이렇게 생성하고 있다. :
getUniqueIndexId - sha1이라는 hash를 통해 그냥 string 을 만들고 있다. sha1은 고유 id를 고유 text 에서 만들어지는 이러한 hash function 입니다.
- 이 hash는 똑같은 문자가 왔을때, 똑같은 코드를 제공해주는 deterministic function 들로 같은 문서가 같은 ID 를 만들 수 있게 제공해주는 이런 FUNCTION 들입니다.
PUT /<target>/_doc/<_id>
POST /<target>/_doc/
PUT /<target>/_create/<_id>
POST /<target>/_create/<_id>formatting function
- json_field_handler
- 만약 json 에 datetime field 가 있으면, 알아듣기 쉬운 isoformat 으로 만들어주는 help function
- json 을 cover datetime 같은 이런 field 들을 json을 convert할때, 에러가 생기지 않게 도와주는 function 이다.
# ingestor/ingestor1.py # Custom handlers for marshalling python object into JSON def json_field_handler(x): if isinstance(x, datetime.datetime): return x.isoformat() raise TypeError(&quot;Unable to parse json field&quot;)
# ingestor/ingestor1.py
# 엘라스틱서치에 출력하는 함수입니다.
def postToElasticSearch(products):
putUrlPrefix = 'http://localhost:9200/products/_doc/'
headers = {'Content-type': 'application/json', 'Accept': 'text/plain'}
for product in products:
id = getUniqueIndexId(product.url)
print(id)
r = requests.put(putUrlPrefix + id, data=json.dumps(product.__dict__, # put 실패하면, 형식과 필드가 일치하는지 다시 확인
indent=4, sort_keys=True, default=json_field_handler), headers=headers)
if r.status_code >= 400: # 에러핸들링용
print("There is an error writing to elasticsearch")
print(r.status_code)
print(r.json())isoformat은 이 파이썬이 제공하는 이런, datetime format 과 다르기 떄문에 이렇게 변경이 필요합니다.
잘 들어왔는지, check_es_index.py 로 확인
# ingestor/tools/check_es_index.py
import requests
url = "http://localhost:9200/products/_search"
payload = {}
headers = {}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)- 결과
$ python tools/check_es_index.py { "took":868, # 걸린 시간 ms 단위이다. ,sql 보다 훨씬 빠른시간, 데이터 수가 많아져도 큰 변화가 생기지 않는다. "timed_out":false, # 타임 아웃이 발생했는가 "_shards":{"total":1,"successful":1,"skipped":0,"failed":0},# shard= 색인을 몇 개로 나누었는지 "hits": { "total":{"value":7,"relation":"eq"}, # hit 이 7개가 되어 돌아옴 "max_score":1.0,# 제일 높은 문서의 score 가 있다. 추 후에 설명 예정 "hits": [ { "_index":"products", "_type":"_doc", "_id":"90063200dc4ce5dc4271f7bb1b9750e481a5c8f6", # 생성된 _id 확인, sha 로 생성된 hex code "_score":1.0, "_source":{ "content": "\ub300\ud615 \ud654\ubd84\uc785\ub2c8\ub2e4. \uc0ac\uc774\uc988\ub294 13\" \uc785\ub2c8\ub2e4.", "id": 10, "image_file": "2021/07/terra-cotta-planter.jpg", "modified_date": "2021-07-02T15:28:15", "post_date": "2021-07-01T18:55:54", "shipped_from": "\ud574\uc678", "title": "\ub300\ud615 \ud14c\ub77c\ucf54\ud0c0 \ud654\ubd84", "url": "http://localhost:8000/?post_type=product&p=10" }},..]}}
직접 elastic search 에 질의 던져보기
- elastic search 에 질의를 직접 검색해볼 수 있게 도와주는
_search라는 API 가 있다. - 원하고 싶은 index 에 _search 를 한 다음 쿼리를 주면, 이쿼리에 대한 결과가 돌아온다.
- 이런 형태로 "장미"라고 던졌을때, 두가지 포스팅이 돌아오는 것을 볼 수 있다.
- http://127.0.0.1:9200/products/_search?q=장미
{ "took":6, # 걸린 시간 ms 단위이다. ,sql 보다 훨씬 빠른시간, 데이터 수가 많아져도 큰 변화가 생기지 않는다. "timed_out":false, # 타임 아웃이 발생했는가 "_shards":{"total":1,"successful":1,"skipped":0,"failed":0},,# shard= 색인을 몇 개로 나누었는지 "hits": { "total":{"value":2,"relation":"eq"},# hit 이 2개가 되어 돌아옴 "max_score":1.2060539,# 제일 높은 문서의 score 가 있다. 추 후에 설명 예정 "hits": [{ "_index":"products", "_type":"_doc", "_id":"a8f6acf14f68c56b2d4edfab139d393a7058f877", "_score":1.2060539, "_source":{ "content": "\ud06c\uace0\uc791\uc740 \ud551\ud06c\uc0c9 \uc7a5\ubbf8\ub4e4\ub85c \ubd80\ucf00\ub97c \ub9cc\ub4e4\uc5b4 \ubcf4\uc558\uc2b5\ub2c8\ub2e4.", "id": 18, "image_file": "2021/07/pink_rose_bouquet.jpg", "modified_date": "2021-07-02T15:27:42", "post_date": "2021-07-01T19:05:02", "shipped_from": "\ud574\uc678", "title": "\ud551\ud06c\ube5b \uc7a5\ubbf8 \ubd80\ucf00", "url": "http://localhost:8000/?post_type=product&p=18" }},... ]}}
플라워몰 웹사이트에 엘라스틱 검색 연결하기
1) 쇼핑몰 : http://127.0.0.1:8000/
2) 검색 페이지 추가 : www/search.php반응형
'SAS' 카테고리의 다른 글
| 패스트 캠퍼스 엘라스틱서치 PART04. 부속 프로세싱 - 이미지 처리 기술과 검색 기술의 융합 (0) | 2021.12.06 |
|---|---|
| 패스트캠퍼스 엘라스틱서치 03. 지식 그래프(knowledge graph)를 활용해 검색 품질 향상하기 (0) | 2021.12.06 |
| sas 공부 이거로 하는중 (0) | 2021.11.05 |